uxtheme.dll a lepší vzhled Windows XP zdarma
Windows XP mají, na rozdíl od Windows 2000, jeden zajímavý doplněk API, a
to je jejich engine témat / vzhledů. Ten sestává z knihovny /windows/system32/uxtheme.dll.
Tato knihovna umí používat *.msstyles soubory, umístěné v /windows/resources/themes/ adresáři,
které definují nejen barvy GUI, ale i řadu jeho ostatních prvků, jako je vzhled
dialogových oken, horní lišty okna, a mnohé další.
Nicméně, nebyl by to Microsoft, aby uxtheme.dll knihovnu neudělal
středně paskvilní, protože akceptuje jen Microsoftem podepsané *.msstyles soubory a nic jiného.
Existují dvě cesty (plus třetí pro Win2k3), jak to obejít:
- Instalovat si testovací verzi StyleXP,
která obsahuje asi desítku nových témat, nový balík ikon, a také memory-patch
pro
uxtheme.dll. - Stáhnout si UXTheme
Multipatcher 2.5.1, který neudělá nic jiného, než že změní pár bajtů
v knihovně uxtheme.dll, tak aby funkce
CryptVerifySig()vždy vracela TRUE, a nezabírá žádné místo v paměti. - Existuje i speciální patch pro Windows 2003 Server, pokud z něj tedy chcete udělat svoji workstation, a funguje jako patch předchozí.
Potom stačí již jen přes menu (v případě StyleXP) nové témata nainstalovat, nebo v případě UXTheme Multipatcher rozbalit a nahrát do patřičného adresáře, a poté ve vlastnostech Zobrazení / Vzhled si toto nové téma můžete zvolit.
Varianta se StyleXP je vhodnější pro ty méně technicky nadané, nicméně, StyleXP
je jen trial verze, a navíc zabírá místo v paměti (jako služba, stačí se podívat
do services.msc). Je nicméně vhodná na občasnou jednorázovou instalaci
nové sady ikon.
Poté, co si upravíte uxtheme.dll, si můžete stáhnout již hotová
témata na neowin.net, themexp.org,
či wincustomize.com.
Existují i jiné skinovací engines, nicméně, ty zabírají daleko více místa v paměti, a jsou méně stabilní. Jejich používání rozhodně nedoporučuji, pokud ovšem nechcete skinovat Windows nižší verze než XP.
Lidé, kteří mají rádi “zaplácaný” desktop bude zajímat i freewarová aplikace TGTSoft SpyderBar, který umí zobrazovat aktuální vytížení počítače, má v sobě RSS/Atom čtečku, napojení na POP3 účty, umí ukazovat počasí v Zimbabwe a Jordánsku, a pár dalších věcí.
Zend’s PHP 5 Coding Contest - Interval.cz
Na Interval.cz vyšel můj článek o Zend’s PHP 5 Coding Contest, první ze série pěti článků. S Vilémem Málkem jsem domluven i na napsání několika článků o JEditu a PHPEclipse.
ProfiMail 1.23 podporuje SSL a Gmail!
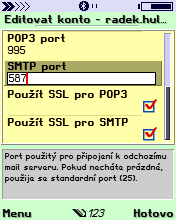
ProfiMail, jednoznačně nejlepší emailový klient pro Symbian telefony, podporuje ve verzi 1.23 rovněž SSL pro POP3/SMTP a custom porty, a je tedy možné jej používat i s gmailem :-)
V e-shopu kupuji zásadně na “dobírku”
Pixy píše o takové všeobecně známé věci, že totiž e-shopy uvádějí jako skladem zboží, které ve skutečnosti skladem nemají. Domníval jsem se, že to je všeobecně známá věc. Osobně si z e-shopů, libovolných, objednávám věci jen na dobírku, a jinak skvělou eBanku bych na zaplacení předem nikdy nepoužil.
Pokud zaplatím předem, je velice těžké dostat peníze zpět.
Objednávka na dobírku má i jiné výhody, pokud zboží uvidím zítra na jiném webu levněji, prostě původní objednávku emailem ihned zruším, a zboží si objednám jinde. Stejně tak, pokud ze dozvím nějaké nové, zásadní informace, a chci si koupit něco jiného, není problém objednávku zrušit…
Navíc, řada e-shopů se sídlem v Praze umožňuje zboží dodat kurýrem do 2 hodin, s předáním peněz v hotovosti přímo kurýrovi (dělá to tak třeba Alzasoft), takže odpadá i jakékoliv chození na poštu, stačí se jen zastavit v nejbližším bankomatu…
Dobírka je prostě velice pohodlný, a hlavně z hlediska zákazníka velice bezpečný způsob, jak nakoupit :-)
Nepoučitelní amatéři

Na interval.cz se objevila další perla do kritiky webu, a to sice dráhaři.info. Nechci se zde (opět) zabývat tím, jak probíhá selekce do kritiky webu, už jsem k ní měl dříve zhruba 1.000 výhrad, zabývat se chci webem dráhaři.info samotným.
Titulní strana tohoto webu nás přivítá originální volbou kódování Windows-1250 nebo ASCII. Hm, zajímavé, co to asi je, řekne si mašinfíra? Neví, tak na něco z toho klikne, a ocitne se zde.
Nevím jak Vy, ale mě trvalo dost dlouho, než jsem přišel na to, že ty prťavé horní (okopírované Pixyho) ikonky jsou ve skutečnosti hlavní navigační menu, a ne ikonky pro RSS exporty a W3C validátor.
Pod těmi ikonkami je potom i nějaký obsah, nicméně, kdo se k němu má dostat??
Nechápu, proč se amatéři snaží dělat věci sami, a špatně. Nejedná se ani tak o to, že je tam nevalidní HTML kód, to je vcelku jedno, katastrofa ale je, že ten web nesplňuje ani z jednoho procenta zásady přístupnosti, použitelnosti, nehovoře o optimalizaci pro SEO, a postrádá rovněž základní funkce, které by takový web měl mít.
Je to prostě zmatený shluk textu, ve kterém se čtenář nemá šanci vyznat.
Přitom by si autor zmíněného webu, webdesignový nedouk, mohl stáhnout zdarma BLOG:CMS, získat zdarma hosting na pipni.cz, a během deseti minut mít systém, který umí články rozčlenit do kategorií, obsahuje diskusní fórum mašinfírů a fotogalerii jejich mašinek, je od počátku navržen jako XHTML 1.0 STRICT validní, jako přístupný a použitelný web, s možností prohledávání článků, s jasně danou navigací, s exportem a tiskem článků, s optimalizací pro SEO, s WYSIWYG editorem, a s řadou dalších věcí.
Nerozumím tomu, proč amatéři, kteří se webdesignu nechtějí věnovat profesionálně, nepoužijí řešení profesionálů, a raději si to doma mastí spokojeně, a zcela špatně, na koleně, a svůj web navíc drze přihlásí do “kritiky webu”… To nečetli kritiky předchozí???
UTF-8

UTF-8 je geniální kódování. Pokud programuji BLOG:CMS, musím pochopitelně počítat s tím, aby onen zdrojový kód běžel bez problémů nejen v Česku, ale i (třeba) v Rusku, Japonsku či Číně. Kdekoliv.
Mírný problém je sice se zpracováním UTF-8 řetězců v PHP, zejména funkce představené
ve stařičkém PHP 3.x s UTF-8 vůbec nepočítají, například takové funkce substr() či strstr()
pracují bajtově, a rovněž tak řada dalších funkcí, nicméně, stále je to menší
problém, než počítat ve Vašem kódu s desítkami různorodých znakových sad.
Nové funkce v PHP 4.3/5.0 navíc již s UTF-8 počítají, včetně funkcí / metod pro práci s XML, neboť UTF-8 je implicitní kódování pro XHTML / XML.
Problémem není ani editace zdrojového textu v UTF-8 na libovolné platformě, jeden z nejlepších programátorských editorů, JEdit, nativně pracuje s UTF-8 a je psaný pod Javou, tudíž běží na každém OS, kde je implementována JVM. Pár lidí používá na Windows rovněž PSPad, nicméně, ten se pro rozsáhlejší projekty skutečně nehodí, a to nejenom proto, že jeho podpora UTF-8 je jen částečná (rozumějte, velice nedostatečná).
Řada nových Linuxových distribucí (SUSE 9.1, Fedora Core 3, MDK 10.1) se rovněž implicitně instaluje s nativní podporou pro Unicode / UTF-8.
Ještě před rokem jsem dělal projekty ve windows-1250, windows-1251, windows-1252, iso-8859-2, iso-8859-1, prostě podle potřeb daného projektu, a řešil jsem řadu problémů při konverzích, a dnes vlastně ani nevím proč jsem už dávno nepoužíval UTF-8. S přechodem na UTF-8 se řada problémů, které člověk s různými kódovými stránkami měl, automaticky vyřešila.
Nebylo by od věci zrušit veškeré existující kódové stránky a schémata, a používat jen UTF-8. Spousta věcí by se dělala mnohem snadněji.
Nenapadá mě rozumný důvod, proč vlastně něco jiného než UTF-8 ještě používat…
PS: ne, úspora pár bajtů a přenosové kapacity ten důvod proti UTF-8 není. Internet zahlcují P2P sítě, ne používání UTF-8.
Libor kuchá telefon

Libor Krayzel (eLKa) na svém webu popisuje drastickou operaci svého mobilu Siemens SX1. Telefon rozebral, urval mu displej, odšrouboval starý joystick, silou tam narval nový joystick z Nokie 6600, poskládal to do sebe, a ono to pak vesele, lépe a radostněji fungovalo.
Jen co seženu joystick z Nokie 6600, jdu do toho taky!
Dokonalá Opera - hledání a search.ini

V následujícím seriálu článků bych se chtěl věnovat konfiguraci Opery 7.60 P3, tak jak ji osobně používám, a pár vychytávkám, které možná neznáte. V tomto prvním díle představím modifikaci hledání v Opeře pro potřeby českých uživatelů.
Modifikace search.ini
Hledání se v Opeře definuje v souboru search.ini, ten Opera hledá
v adresáři instalovaného programu, popřípadě v podadresáři /profile/.
Sestavil jsem search.ini, které již delší dobu používám, obsahuje 15 vyhledávačů,
překladačů a slovníků, které potřebuji a používám, včetně definice zkratek pro
rychlé vyhledávání.
Pokud je například u google.com uvedena zkratka g, postačí
v adresním řádku
místo URL zadat g
slovo,
a už hledáte (stiskněte klávesu F2, a napiště g slovo!). Mimořádně
rychlé a efektivní…
Nadefinované search engines a zkratky:
| Search engine | Zkratka |
|---|---|
| g | |
| AllTheWeb | a |
| Find in page | f |
| Jyxo | j |
| Seznam | s |
| Centrum | c |
| Atlas | t |
| Překlad aj->čj | ac |
| Překlad čj->aj | ca |
| Astalavista | crack |
| Hudba | m |
| Merriam-Webster slovník | mw |
| Urban dictionary | ud |
| The New Thesaurus | nt |
| Dictionary.com | d |
| English spellchecker | sp |
Celý soubor ke stažení: search.ini.
IRC EFnet není pro CDMA
CDMA používá několik desítek tisíc lidí, a všichni mají, bohužel, stejnou IP adresu. Potom to znamená jednoho blbce, a vidíte toto:

Jak poznáte, kdy Vás google indexoval?
Ne, nepotřebujete na to žádný log, a poznáte přesto přesně datum a čas, kdy Vás google.com indexoval. Stačí na Vaši stránku umístit datum a čas jejího vytvoření (to dělám v mém případě, protože se statické stránky vytváří redakčním systémem automaticky, po 30 minutách), nebo přímo aktuální datum a čas, a potom se podíváte na cache stránky google.com pro myego.cz/ a uvidíte:
vytvořeno v 05:29:39, 16.11.04 za 0.00075s | z cache: Ano
Jinak řečeno, google.com můj web na novém webhostingu opět zaindexoval včera ráno…
Radek Hulán

 Twitter Twitter |
 Facebook Facebook |
navigace
kategorie
- Hardware
- PPC Hardware
- HTechnologie
- TThinkPad
- Hry
- HHry na PC
- XXBox 360
- Kavárna
- AAuta
- CCyklistika
- HHudba
- LLyžování
- MMám rád...
- Linux a OS X
- AApple OS X
- LLinux
- Microsoft Windows
- BBezpečnost
- SSoftware
- 7Windows 7
- VWindows Vista
- XWindows XP
- Společnost
- BBusiness
- SSpolečnost a politika
- TTiskové zprávy
- Telefony a čtečky
- KAmazon Kindle
- AAndroid
- SSymbian
- WWindows Mobile
- Webdesign
- AAdobe a grafika
- GGoogle
- PPHP
- WWebdesign, CMS
aktivní diskuse
- Proč používat "klikněte zde"? 29.02.20 12:40
- hulan.cz/blog » myego.cz 17.02.20 05:57
- Therapia - ergonomická kancelářská židle, do které se zamilujete 31.12.19 11:07
- Toto je validní -//WellDone//DTD XHTML-with iframe 1.1//EN! 23.12.19 17:28
- .htaccess a FilesMatch pro SEO URL 23.12.19 17:21
nejčtenější články
- FIREWALL - základ bezpečnosti (díl 1/3)
- Bajka o zodpovědnosti za svůj život
- Sparta nebo Slávie?
- Jak zabezpečit domácí Wifi router / síť - WPA / WEP
- Screenshoty ze současných top her