Koupíte si tištěnou knihu a máte fantastickou čtečku elektronických knih - Amazon Kindle. Co uděláte? Knihu vložíte do scanneru a pomocí OCR převedete do formátu, kterému Kindle rozumí. Zabere vám to celé zhruba hodinu až dvě.
Zkoumal jsem různá OCR řešení a jako nejlepší v současné době se mi jeví ABBYY FineReader 10 Professional. Prodává se v krabicové verzi za cca 3.000 Kč + DPH (SW.cz).
Co se mi na něm hlavně líbí? ABBYY FineReader funguje rychle a spolehlivě, OCR je bezchybné, obsahuje řadu slovníků (několik desítek), spolupracuje s Microsoft Wordem při kontrole pravopisu, umí se učit nové znaky, rozezná záhlaví, zápatí a čísla stránek a správně je označí v rozpoznaném dokumentu (takže nejsou součástí textu knihy).
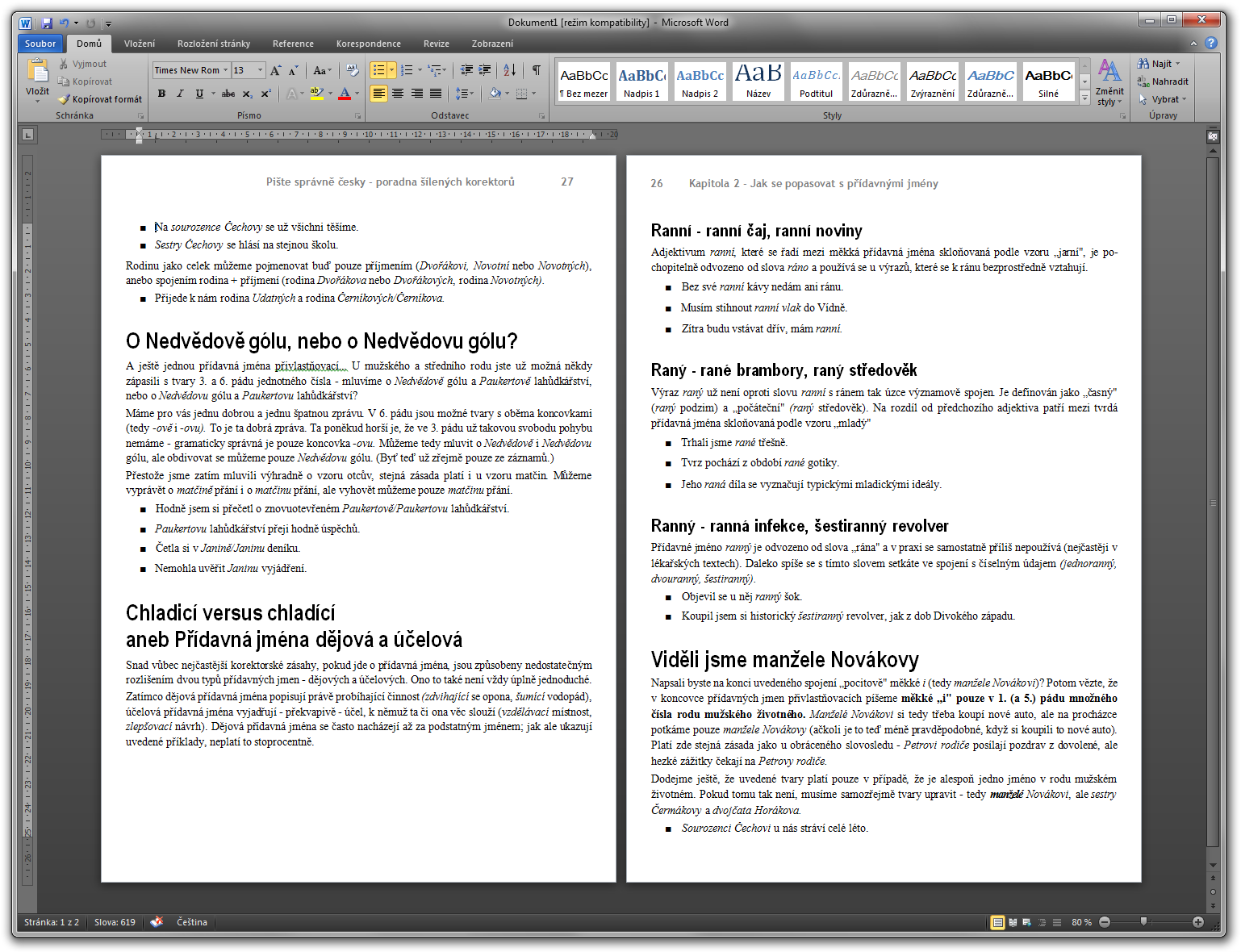
Základem je samozřejmě naskenování dané knihy (používám Canon MP640 multifunkční tiskárnu / skener; kniha v ukázce je Pište správně česky - poradna šílených korektorů). Skenování je maximálně zjednodušeno přes WIA/TWAIN ovladače, takže jen otáčíte listy knihy a mačkáte tlačítko "Skenovat", podle potřeby můžete ale samozřejmě použít nativní ovladače skeneru:
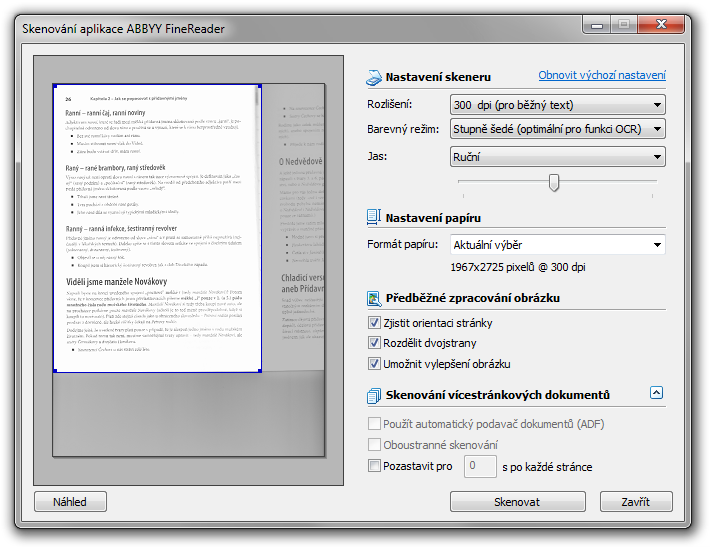
skenování knihy
Následně si můžete určit jazyky, které budou použity pro rozpoznání tohoto dokumentu - k dispozici je jich několik desítek, včetně podpory pro speciální technické a matematické symboly:
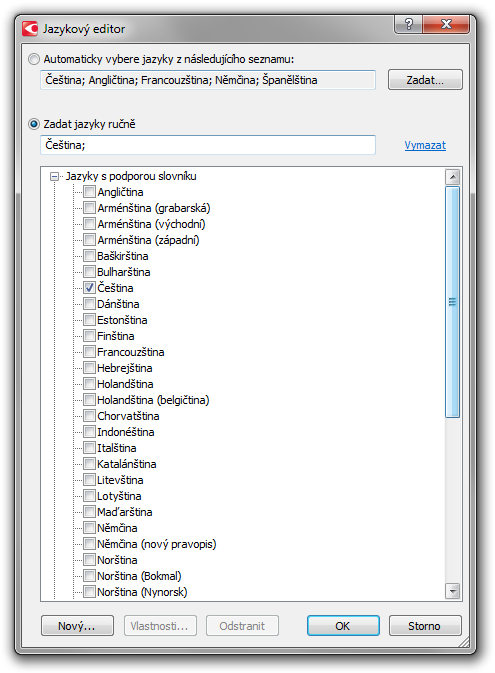
jazyky rozpoznávaného textu
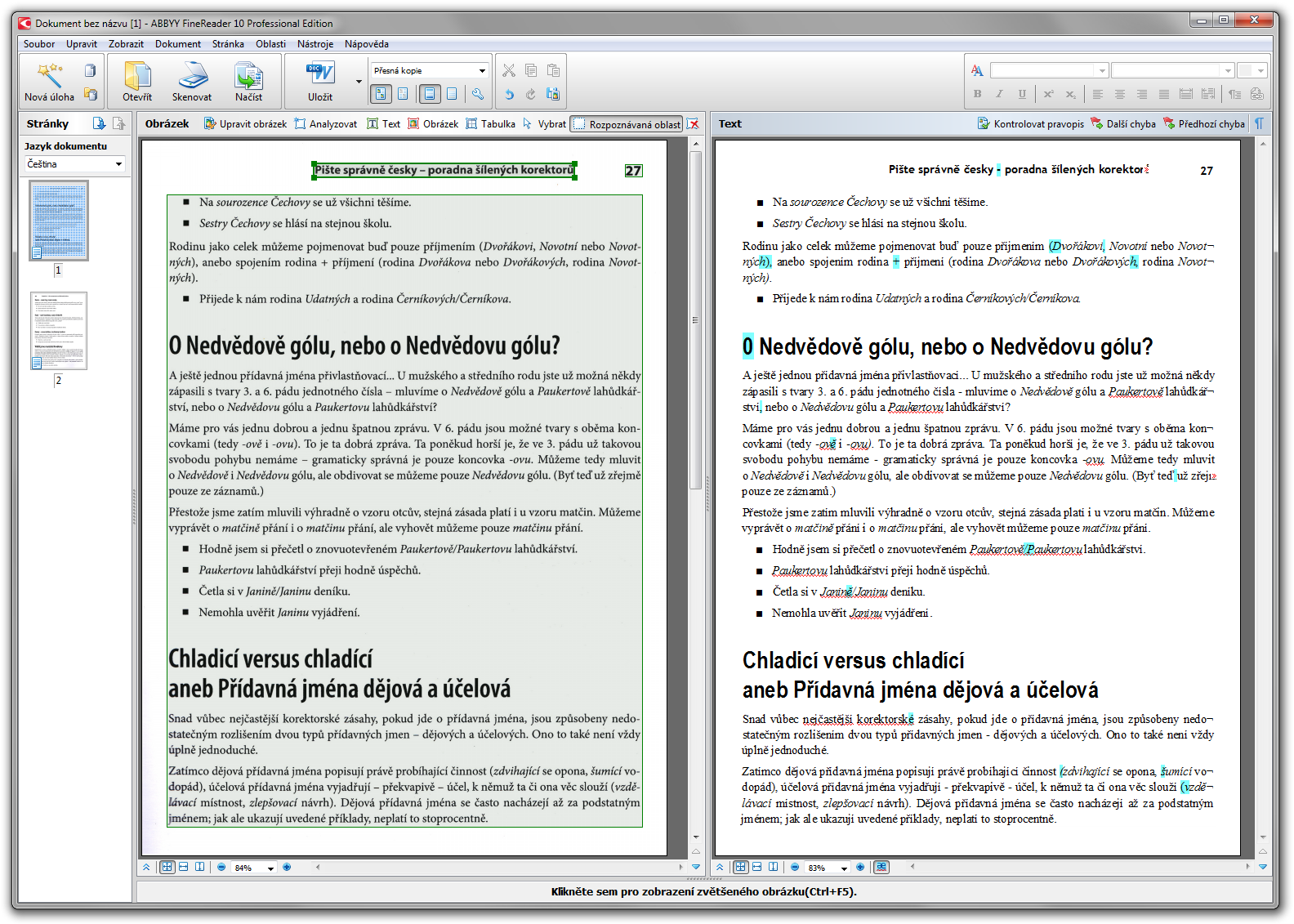
ABBYY FineReader 10 automaticky rozpozná jednotlivé oblasti textu, obrázků, tabulek a záhlaví a převede je do upravitelného textu, v tomto případě bez jediné chyby (pouze písmeno "O", co vypadalo v originále jako "0", převedl jako číslici, což se ale nedá chápat jako chyba):
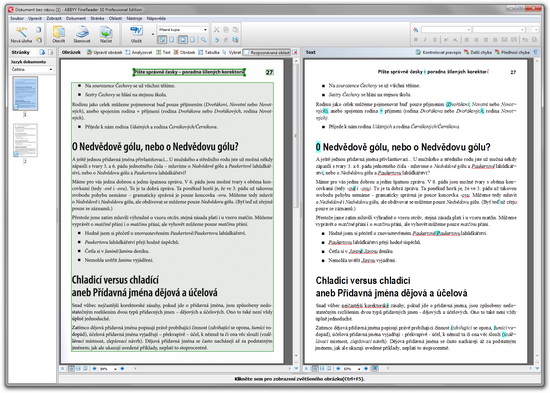
ABBY FineReader 10
Pokud je to potřeba, můžete snadno v textu opravit pravopis, vidíte samozřejmě jak původní kus naskenovaného materiálu, tak text rozpoznaný pomocí OCR. Možné chyby jsou vysvíceny modrou barvou:
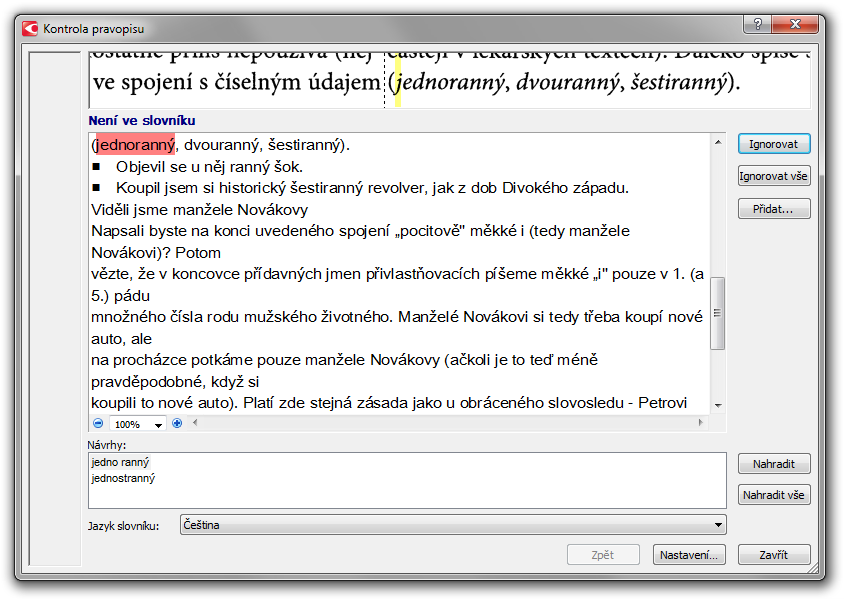
kontrola pravopisu
ABBYY FineReader umí rozpoznat určité speciální bloky textu - číslování stránek, záhlaví, zápatí. Toto je důležité, protože je jako speciální bloky také následně ukládá do Wordu či PDF a nestávají se součástí hlavního textu knihy:
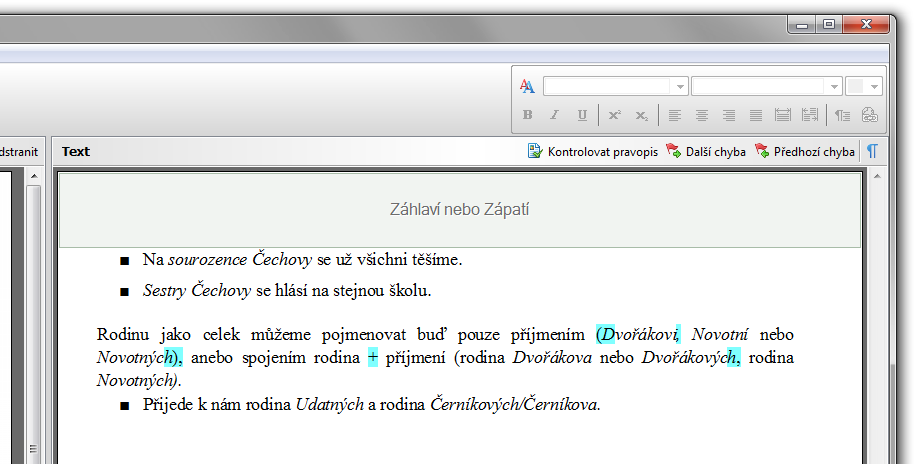
záhlaví a zápatí
Uložení rozpoznaného textu je možné do řady formátů - Wordu (DOC, RTF), XLS, PDF, PPTX či prostého TXT nebo CSV:
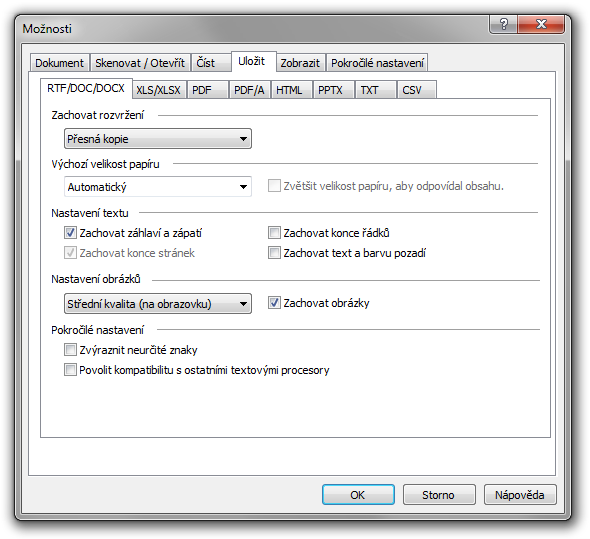
možnosti uložení dokumentu
Takto poté vypadá rozpoznaná knížka ve Wordu 2010:
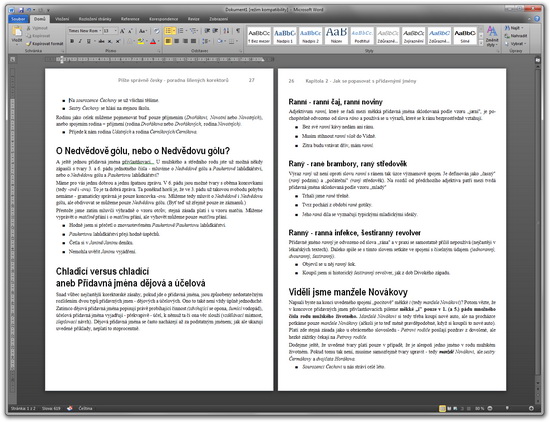
knížka ve Wordu 2010
A pokud chcete, jediným stisknutím tlačítka "Převod" v Calibre vytvoříte z DOC/RTF formátu MOBI formát, který již můžete číst ve vašem Amazon Kindle nebo Mobipocket Readeru na PC:

knížka v MOBI formátu
ABBYY FineReader 10 Professional je výboné řešení pro převod tištěných textů do PDF. Nemusí se jednat samozřejmě jen o knížky, bezvadně převede i formuláře, PDF a další.
Nedávno jsem dostával jeden přihlašovací formulář v PDF, jehož obsahem nebyla editovatelná tabulka, ale naskenovaná bitmapa. Převod pomocí OCR dokonale zachoval celou strukturu formuláře, uložil jsem jej do Wordu, a řada lidí si jej mohla během minuty pohodlně vyplnit. Bez kvalitního OCR by to nešlo.
Stejně tak stále dostáváme spousta (starších) podkladů od klientů, které jsou v tištěné podobě, ale ne elektronické, zde dobré OCR usnadní obrovskou spoustu práce.
Zajímalo by mne, jak rychle naskenujete 1 stránku, protože knížka co má 200 - 300 stránek naskenovaná za 1 - 2 hodiny je opravdu rychlost.
V automatickém módu pro vícestránkové dokumenty (knihy) ani není třeba mačkat tlačítko skenovat, stačí nastavit čas, který člověk chce mít na otočení listu.
Nemůžu, než souhlasit. Abby FR mi vyšel jako nejlepší už před několika lety a doporučil jsem jej několika svým klientům.
Doplnil bych snad jen, že je schopen rozpoznat text i na poměrně nekvalitní (zdeformované) fotografii (např. když si vyfotím plakát) - nejenže rozpozná případné otočení snímku, ale i v případě jeho deformace (např. zkosení způsobené pořízením snímku z určitého úhlu) provede při jeho prvotní analýze vyrovnání obrazu, aby řádky byly horizontálně.
Dále není na škodu podotknout, že Abby velmi dobře umí zpracovat nejen data ze skeneru, ale třeba i z PDF a to jak textového, tak i v případě, že PDF je pouze obálka na již dříve oskenovaný dokument.
Abby také podporuje serverovou verzi, kdy do sdíleného adresáře na serveru nahrajete (jakkoliv, třeba i přes FTP) zdrojová data (obrázek, PDF, cokoliv) a během okamžiku se tamtéž objeví Wordový dokument obsahující zpracované data - lze jej tedy použít i prostředí s velkým množstvím uživatelů.
Mám taký dotaz. Mám PDFko s naskenovanými obrázkami na ktorých je text - je to časť knihy, ale je to proste naskenované ako obrázky a uložené do PDF.
Je možné toto dostať cez Abby FR do textovej podoby tak, aby to šlo použiť povedzme v Kindle a pod.?
[4] jo, z PDF obsahujícím vlastně JPEG se dá dělat v ABBYY pomocí OCR text
Já bych měl otázku jestli existuje nějaký formát, se kterým by si poradil Kindle, ale dokázal by udržet rozložení stránky tak, jak je v originální předloze (na stránce jsou tabulky, obrázky, mezi tím obtéká text). Jde mi o to, jestli existuje nějaký formát pro Kindle, alternativní k PDF, kde musím neustále posunovat obraz všemi směry, abych si dokument přečetl.